Identifying Risk Predictors for Self-Harm through Electronic Medical Records
Ideas from Czyz et al. 2021 and Huang et al. 2020
Dataset Overview
- Overview of the data can be found here
Project Goals
- Can we identify reliable proximal markers of suicide risk to inform personalized interventions provided at crucial moments in the individual’s natural environment?
- Validated indicators of proximal risk could lead to the development of adaptive interventions
- Short-term risk prediction is a key concern for clinical providers and more research that incorporates proximal assessment is needed to provide insights about short-term precursors to suicidal ideation in order to facilitate early detection of risk as well as inform targeted interventions.
- Are existing tools/models validated on diverse communities of adolescents?
- There is a great need to ensure that screening tools serve youth from diverse backgrounds, identities, and cultures.
- One major goal of this work would be to integrate screening into clinical practice.
- Any models that we build should be interpretable and any uncertainty (statistical or otherwise) should be clearly communicated.
- Are there environmental predictors of suicide risk? Can this be identified using geocoded data?
- What is the scope/granularity of the geocoded data collected by CHOP?
- Can the model that we build on CHOP data be generalized to adolescents in other geographical locations? For example, are there similar risk predictors for suicide in Philadelphia compared to Boston?
- Was COVID-19 a risk factor of suicide attempt?
- Can we quantify the risk that COVID presented to a population at-risk for suicide? Were suicide risk predictors different as a result of the pandemic?
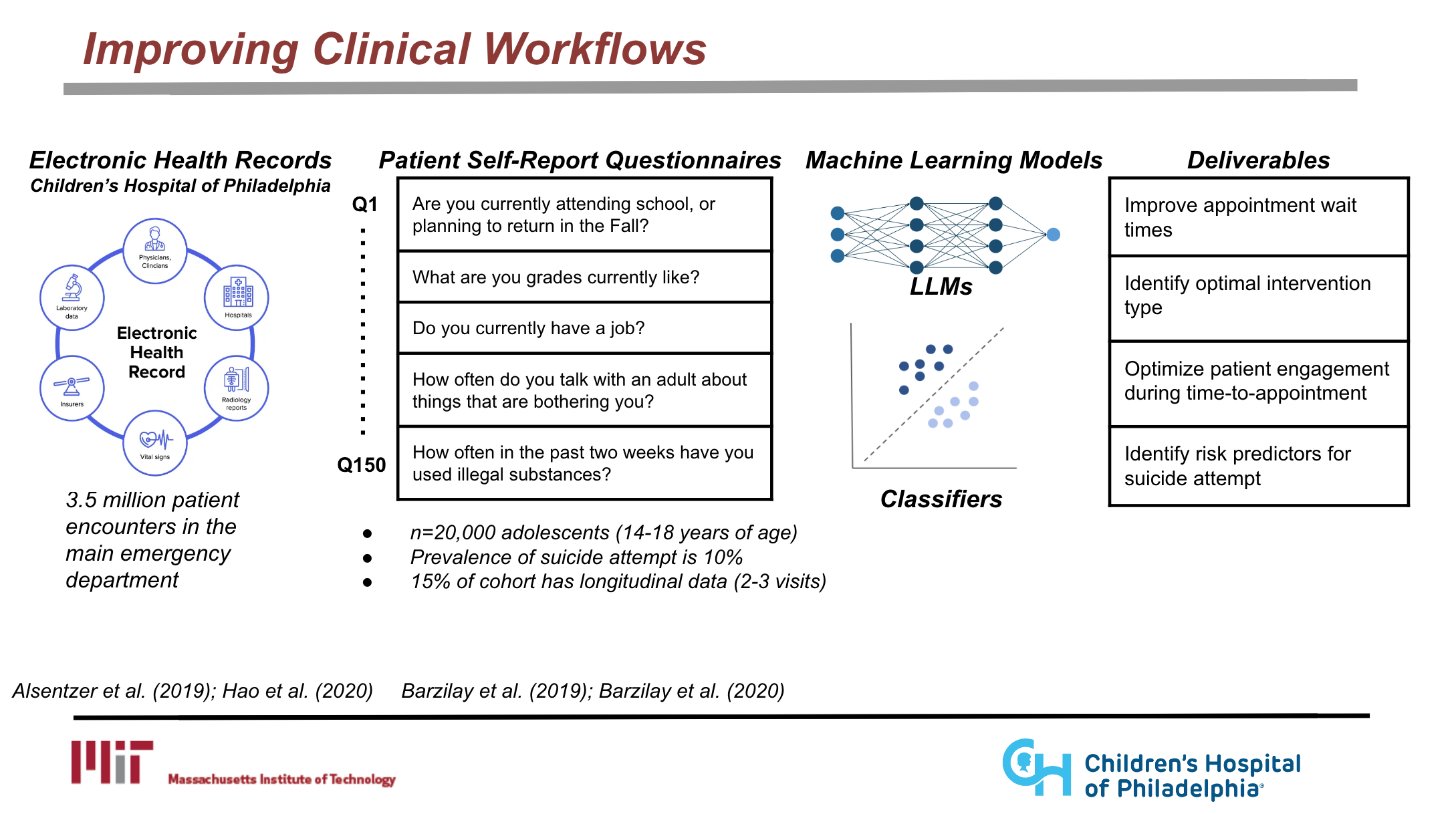
Methods
- One idea for modeling the data is to use clinicalBERT, which models clinical notes to predict hospital readmission. This approach is largely focused on unstructured data, therefore it should be applied to electronic health records that contain text data, which are high-dimensional and sparse.
- To model structured data, we could use any number of machine learning pipelines. We are using pydra-ml for another project, which is a lightweight and flexible machine learning pipeline that does predictive (and interpretable) modeling.
Ethical considerations
- Not only are there methodological considerations for anyone doing predictive modeling work in psychiatry, but there are significant ethical considerations. As we progress in this project, I hope to be mindful of these points and to include them in our discussions wherever possible.