Feature Engineering
What is feature engineering?
- preprocessing steps that transform raw data into features that can be used in ML algorithms such as predictive models.
- It is during the feature engineering process that the most useful predictor variables are created an selected for the predictive model.
- four main steps: feature creation, transformations, feature extraction, and feature selection
Feature creation
- identifiying variables that will be most useful in the predictive model
- subjective process, requiring human intervention
Transformations
- manipulating predictor variables to improve model performance (e.g., scaling etc.)
Feature extraction
- automatic creation of new variables by extracting them from raw data - reducing the volume of data into a more manageable set for modeling (e.g., cluster analysis, edge detection, pca)
Feature Selection
- these algorithms analyze and rank various features to determine which features are irrelevant and should be removed, which features are redundant etc. which features are most useful for the model and should therefore be prioritized.
Why is feature selection important?
simplify the model by reducing the number of parameters
decrease training time
reduce overfitting by enhancing generalization
avoid the curse of dimensionality
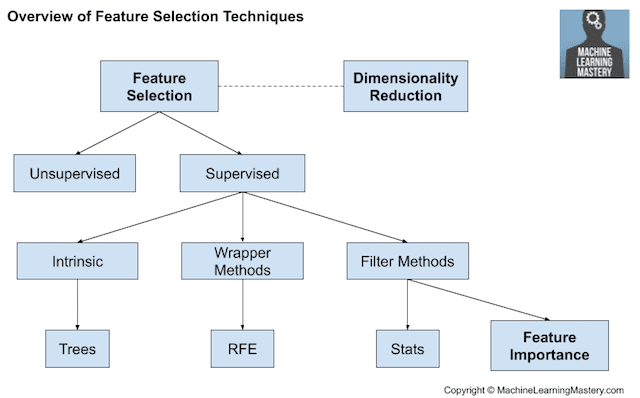
- Supervised options:
- Filtering based on some criterion (correlation between variables) - feature importance
- Search problem: wrapped-based solution that selects features using something like recursive feature elimination
- Embedding/Intrinsic: algorithms like Lasso and random forest have built-in feature selection methods
- Unsupervised
- These methods don’t have target variable - instead remove redundant variables
- Dimensionality Reduction
- Project input data into a lower-dimensional feature space
- Supervised options:
Feature Selection: Exploratory
- Feature importance:
- gives you a score for each feature of your data, the higher the score, the more important or relevent that feature is to your target feature
- inbuilt sklearn classes: random forest classifiers
from sklearn.ensemble import ExtraTreesClassifier
- Correlation matrix heatmap
- shows how features are related to each other or the target feature
sns.heatmap
- shows how features are related to each other or the target feature